hybrid-vocal-classifier (hvc)¶
a Python machine learning library for animal vocalizations and bioacoustics¶
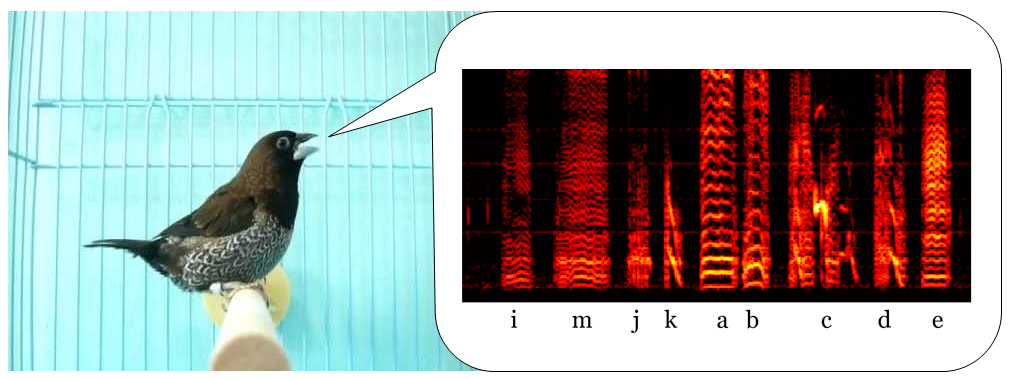
the hybrid-vocal-classifier library (hvc for short)
makes it easier for researchers studying
animal vocalizations and bioacoustics
to apply machine learning algorithms to their data.
Its focus on automating the sort of annotations
often used by researchers studying
vocal learning
sets hvc apart from more general software tools for bioacoustics.
In addition to automating annotation of data,
hvc aims to make it easy for you to compare
different machine learning models that researchers have proposed,
using the data you have in your lab,
so you can see for yourself which one works best for your needs.
A related goal is to help you figure out
just how much data you have to label to get “good enough” accuracy for your analyses.
You can think of hvc as a high-level wrapper around
the scikit-learn library,
plus built-in functionality for working with annotated animal sounds.
Running hvc requires almost no coding.
Users write simple Python scripts, and most will have to only
adapt the examples from the documentation. Large batch jobs can be
run with configuration files written in YAML,
an easy-to-read format commonly used for configuration files.
Again, most users will only have to copy the example .yml files
and then change a couple of options to work with their own datasets.
This code sample gives a high-level view of how you run hvc:
import hvc
# extract features from audio to train machine learning models
hvc.extract('extract_config.yml') # using .yml config file
# train models/classifiers and select model with best accuracy
hvc.select('select_config.yml')
# use trained model to predict labels for unlabeled data
hvc.predict('predict_config.yml')
Advantages of hybrid-vocal-classifier¶
- frees up hundreds of hours spent annotating data by hand
- completely open source, free
- makes it easy to compare multiple machine learning algorithms
- almost no coding required, configurable with text files
- built on top of Python packages road-tested by the greater data-science community:
- numpy , scipy , matplotlib , scikit-learn , keras
Documentation¶
Installation¶
see Installation
Support¶
Contribute¶
- Issue Tracker: https://github.com/NickleDave/hybrid-vocal-classifier/issues
- Source Code: https://github.com/NickleDave/hybrid-vocal-classifier/
License¶
BSD license.
Citations, repositories, and related work¶
Code of Conduct¶
We welcome contributions to the codebase and the documentation, and are happy to help first-time contributors through the process. Project maintainers and contributors are expected to uphold the code of conduct described here: Contributor Covenant Code of Conduct
Backstory¶
hvc was originally developed in the Sober lab
as a tool to automate annotation of birdsong (as shown in the picture above).
It grew out of a submission to the
SciPy 2016 conference
and later developed into a library,
as presented in this talk: https://youtu.be/BwNeVNou9-s